Episerver Commerce Catalog import using Azure Storage and Azure Webjobs
The task at hand
In a recent Episerver Commerce project we had to write a product import integration were our starting point was this:
- The customer did not have a PIM system
- Every night their systems produced a csv-file containing all product information, including prices and stock for each store
- There were no delta files available
- The catalog size was +100 000 products, and with separate lines for each store the .csv file had more than 1 mill lines.
The obvious issues
We did have one initial go at creating a scheduled job where we parsed the file, having it memory while working against Episerver, but that did not go well. Basically the memory usage skyrocked and eventually the app-pool recycled itself since it was consuming 90 % of memory. Also, having a long running job processing this huge amount of data inside a web site is not ideal.
Azure table storage and storage queues to the rescue
Due to the amount of data we started working on an idea to create a delta import by comparing todays file with yesterdays file, and only adding the changed product-ids to a queue. The fastest way to compare would be to work on the same data model as the mapped model from the file. Since the site was running in Azure, Azure Table Storage and Azure Storage Queues was a good fit for this. Here are some useful links for those new to Azure storage and/or WebJobs:
We came up with following apporach:
Part 1: process incoming file, create delta, update table and add only changed items to queue
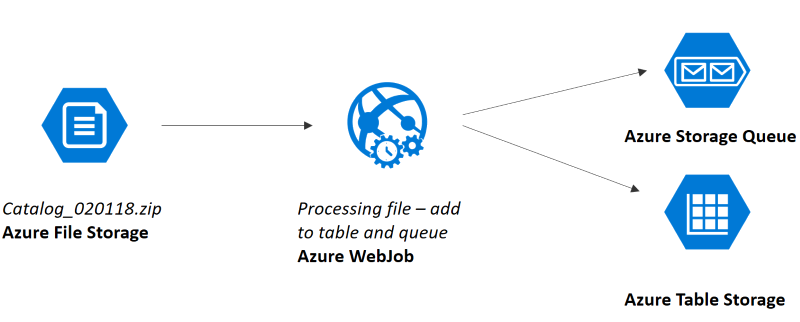
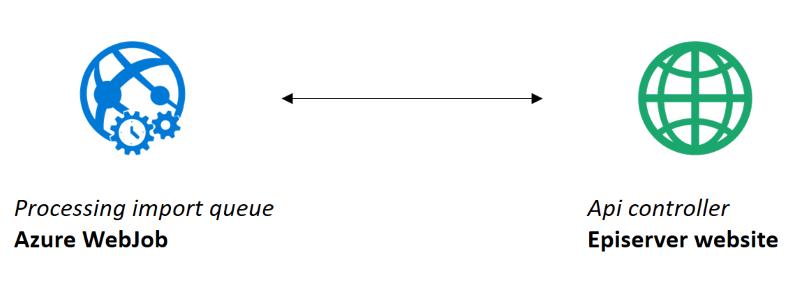
Part 2: process items in queue and do actual import
Creating the delta
By comparing the current file to process with existing table data we were able to compute a delta. This was a bit problematic as the product sort order was calculated based on items sold which resulted in pretty much all products being part of the delta.
The site had click and collect functionality with no active tracking of stock other than "In stock", "Out of stock" flags.
By taking sortorder and stock out of the delta eqation we ended up with a resonable delta to process. Instead of processing +100 000 rows, we now only have 4000-15 000 items to process each night.
We solved sort order by doing a query to azure table storage when indexing – that way we ensured that sort order was updated even if it was not part of delta compare.
Using WebJobs and queues for long running background tasks
WebJobs is a feature of Azure App Service that enables you to run a program or script in the same context as the web app. There is no additional cost to use WebJobs, and they can be triggered manually or by event, scheduled or run continously. There are obvious benefits with running the import as a background task:
- Import can be stopped and re-started - the job will continue with items left on queue
- Site can be restarted without crashing import
We decided to keep the webJobs separate in terms of dependencies towards Episerver , i.e. there are no reference to Episerver in any of the webJobs. Their main tasks is to work against the Azure tables and queues. Because of this, we have an api controller that does the "actual work" of creating/updating episerver data.
With a setup like this it's important to secure calls to the api controller - we used key/secret implementation for this. The api controller receives a queue batch (32 messages) per request and processes the messages in parallell - with locking on Save method.
Only update relevant data
The product information comes from 3 different sources:
- Product and price data from file/Azure table
- Product data from external web service
- Images and documentation from external web service
Therefore our queue message object contains flags indicating what data is needed upon update/creation. These flags are set as part of the initial file processing webjob.
public class QueueMessage
{
public int ProductCode { get; set; }
public bool UpdateEpi { get; set; }
public bool NeedsData { get; set; }
public bool NeedsMedia { get; set; }
}
Working with Azure Storage
There are a couple of nice-to-know tweaks in order to speed up performance when working against Azure storage. The short story is to make sure you work with batches when updating storage table or reading from queue.
For more in-depth knowledge I recommend reading the following (extremly long but very useful) article by Troy Hunt:
https://www.troyhunt.com/working-with-154-million-records-on/
Kontakt oss her
